
Embedding Math

Embeddings in large language models (LLMs) are crucial for how these models understand and generate language. At the heart of embeddings is the representation of words as vectors in a high-dimensional space, capturing both semantic and syntactic nuances.
Vectors and Tokenization
In machine learning, words or tokens are represented as vectors, which are essentially lists of numbers that encode meaning. Tokenization splits text into smaller units, like words or subwords, each mapped to a unique vector. These vectors are learned to ensure words with similar meanings are close in this space, allowing models to understand relationships like "king" and "queen."
Geometry of Embeddings
The geometry of vector space is key to how LLMs interpret language. Each dimension can represent a linguistic feature, such as living beings or tense. A word's position is a combination of these dimensions, enabling the model to capture complex relationships. Properly tuned embeddings cluster similar words, aiding tasks like analogy and similarity detection.
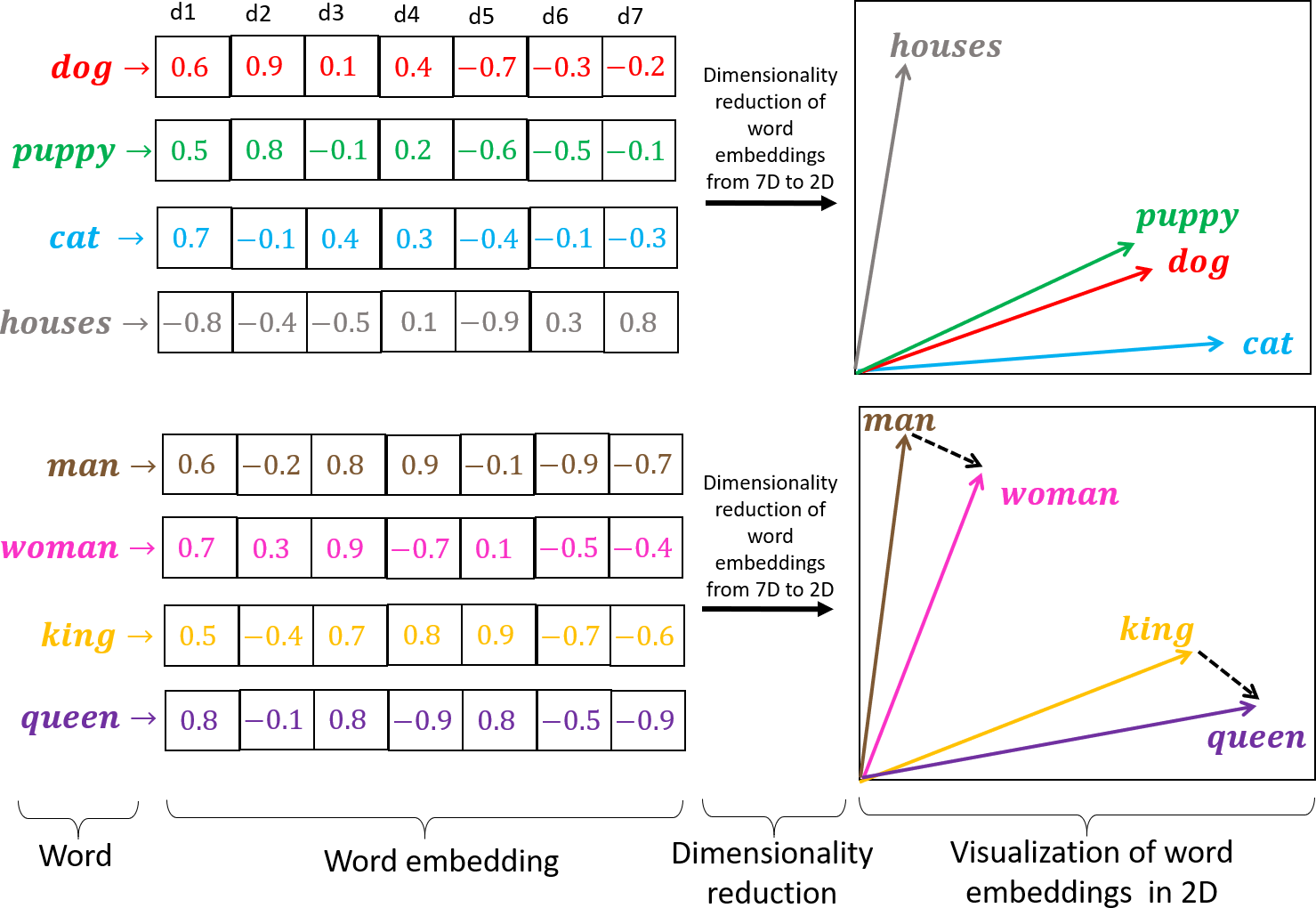
Embeddings capture consistent offsets between words, allowing for analogical reasoning. For instance, the vector difference between "king" and "queen" mirrors that between "man" and "woman," reflecting a gender relationship. This enables LLMs to solve analogies like "man is to woman as king is to ?."
Embeddings transform language into a structured form, enabling LLMs to understand and generate text accurately by leveraging vector space geometry.
Embeddings and document retrieval
Embeddings play a pivotal role in how RAG ends up works. Selecting the right embedding model, particularly one that is fine-tuned for the specific domain, can significantly improve retrieval accuracy. Additionally, exploring different indexing strategies, such as combining keyword-based search with semantic matching, can optimize the retrieval process. This hybrid approach leverages the strengths of both methods, ensuring that the system can handle a wide range of queries effectively.
As the retrieval corpus grows, maintaining scalability and efficiency becomes a challenge. Developers need to design scalable architectures that can handle large datasets and perform real-time retrieval. This may involve optimizing retrieval algorithms and employing cloud-based solutions to manage computational demands. Ensuring that the system can scale seamlessly is essential for maintaining performance as data and user loads increase.
Did I got something wrong? Have a thought? Email me immediately. See you tomorrow!